FineCog-Nav: Integrating Fine-grained Cognitive Modules for Zero-shot Multimodal UAV Navigation
CVPR 2026 Findings
📄 Paper 📝 arXiv 💻 Code 💾 Dataset

Poster
Demo Video
CVPR 2026 Findings
📄 Paper 📝 arXiv 💻 Code 💾 Dataset
Poster
Demo Video
Abstract
Teaser
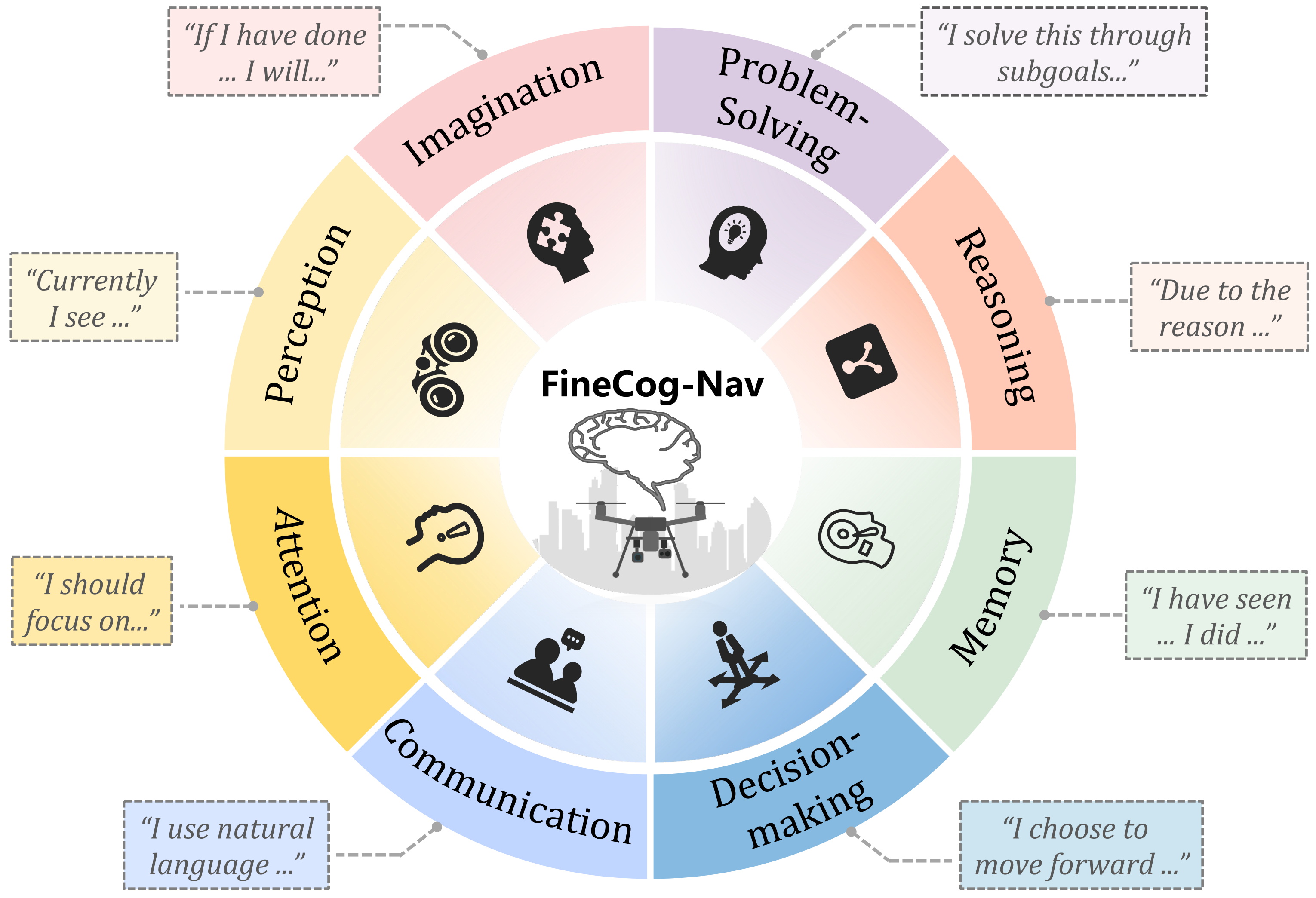
UAV vision-language navigation (VLN) requires an agent to navigate complex 3D environments from an egocentric perspective while following ambiguous multi-step instructions over long horizons. Existing zero-shot methods remain limited, as they often rely on large base models, generic prompts, and loosely coordinated modules. In this work, we propose FineCog-Nav, a top-down framework inspired by human cognition that organizes navigation into fine-grained modules for language processing, perception, attention, memory, imagination, reasoning, planning, and decision-making. Each module is driven by a moderate-sized foundation model with role-specific prompts and structured input-output protocols, enabling effective collaboration and improved interpretability. To support fine-grained evaluation, we construct AerialVLN-Fine, a curated benchmark of 300 trajectories derived from AerialVLN, with sentence-level instruction-trajectory alignment and refined instructions containing explicit visual endpoints and landmark references. Experiments show that FineCog-Nav consistently outperforms zero-shot baselines in instruction adherence, long-horizon planning, and generalization to unseen environments. These results suggest the effectiveness of fine-grained cognitive modularization for zero-shot aerial navigation.
Method
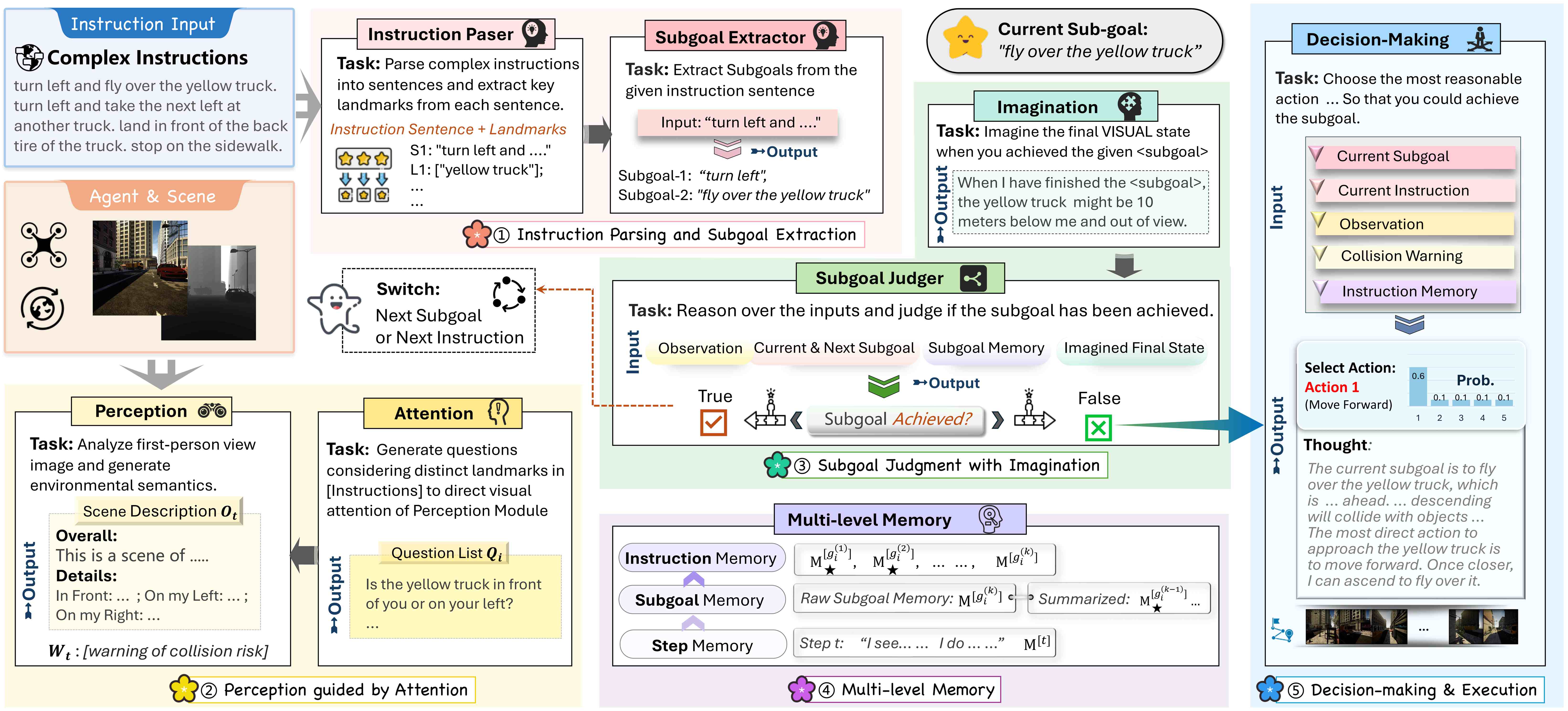
FineCog-Nav Framework Pipeline
FineCog-Nav organizes zero-shot UAV navigation into a closed cognitive loop: (1) instruction parsing and subgoal extraction, (2) attention-guided perception, (3) imagination-assisted subgoal judgment, (4) multi-level memory management at step/subgoal/instruction granularity, and (5) explainable decision-making with collision-aware action selection. This modular interdependence improves interpretability and task progression over monolithic prompting pipelines.
Task objective: let the final UAV position $p_{stop}$ approach destination $p_{dest}$ under threshold $\delta$, i.e. $\|p_{stop} - p_{dest}\| \leq \delta$. The action space includes movement, turning, altitude changes, and task completion.
Experimental Results
We evaluate several base LLMs with basic prompts, forming single-module baselines referred to as BaseModels. For a fair and meaningful comparison, all experiments are conducted on AerialVLN-Fine, which provides a cleaner and more discriminative benchmark. FineCog-Nav consistently outperforms BaseModel across metrics.
| Model | Method | SR2D (%) | SR3D (%) | OSR (%) | NE (m) | nDTW (%) | PL (m) | Steps |
|---|---|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | BaseModel | 1.33 | 1.00 | 3.67 | 240.04 | 8.84 | 329.78 | 129.70 |
| Gemini 2.5 Flash-Lite | FineCog-Nav | 4.00 | 2.67 | 6.33 | 120.70 | 15.66 | 146.24 | 57.52 |
| GPT-4o-mini | BaseModel | 0.33 | 0.33 | 2.00 | 325.98 | 8.74 | 350.43 | 103.10 |
| GPT-4o-mini | FineCog-Nav | 4.00 | 2.33 | 3.67 | 100.37 | 20.45 | 56.98 | 31.73 |
| InternLM3-8B | BaseModel | 0.67 | 0.33 | 3.33 | 128.13 | 14.01 | 86.30 | 34.65 |
| InternLM3-8B | FineCog-Nav | 2.67 | 2.33 | 6.67 | 120.72 | 14.91 | 139.72 | 42.22 |
| ChatGLM-4-9B | BaseModel | 1.00 | 0.33 | 1.33 | 124.03 | 13.27 | 50.19 | 20.36 |
| ChatGLM-4-9B | FineCog-Nav | 3.00 | 2.67 | 2.67 | 97.05 | 19.26 | 30.49 | 19.39 |
| InternLM2.5-20B | BaseModel | 0.33 | 0.33 | 1.67 | 152.34 | 9.94 | 141.27 | 74.16 |
| InternLM2.5-20B | FineCog-Nav | 2.00 | 2.00 | 4.00 | 103.94 | 19.35 | 61.05 | 28.49 |
| ChatGLM-4-32B | BaseModel | 2.33 | 2.00 | 5.00 | 180.66 | 10.59 | 235.03 | 104.20 |
| ChatGLM-4-32B | FineCog-Nav | 3.33 | 2.33 | 5.33 | 94.18 | 21.25 | 45.91 | 20.18 |
| Qwen3-32B | BaseModel | 2.67 | 3.00 | 6.33 | 142.72 | 17.07 | 114.56 | 39.12 |
| Qwen3-32B | FineCog-Nav | 5.00 | 4.00 | 7.00 | 95.31 | 20.31 | 60.36 | 26.05 |
| Llama3.3-70B | BaseModel | 3.00 | 2.67 | 5.67 | 263.10 | 9.67 | 329.36 | 111.48 |
| Llama3.3-70B | FineCog-Nav | 6.67 | 6.00 | 9.67 | 98.84 | 20.17 | 84.96 | 38.91 |
| Qwen2.5-72B | BaseModel | 2.67 | 2.67 | 6.33 | 270.10 | 10.69 | 298.24 | 116.91 |
| Qwen2.5-72B | FineCog-Nav | 8.00 | 6.00 | 9.00 | 91.43 | 22.48 | 67.96 | 33.90 |
We first evaluate on AerialVLN-Fine, followed by scalable experiments on the larger and noisier AerialVLN-S-Val subset. Across both datasets, FineCog-Nav consistently outperforms all baselines across all metrics, validating the efficacy of the cognitive collaborative framework.
| Dataset | Method | SR2D (%) | SR3D (%) | OSR (%) | nDTW (%) | NE (m) | PL (m) | Steps |
|---|---|---|---|---|---|---|---|---|
| AerialVLN-Fine | NavGPT | 0.33 | 0.00 | 0.67 | 15.90 | 110.94 | 21.44 | 9.33 |
| AerialVLN-Fine | DiscussNav | 2.67 | 2.67 | 3.33 | 19.63 | 98.36 | 39.51 | 17.76 |
| AerialVLN-Fine | FineCog-Nav | 8.00 | 6.00 | 9.00 | 22.48 | 91.43 | 67.96 | 33.90 |
| AerialVLN-S-Val | NavGPT | 0.12 | 0.12 | 0.46 | 8.29 | 135.65 | 44.92 | 13.02 |
| AerialVLN-S-Val | DiscussNav | 0.46 | 0.46 | 0.93 | 8.33 | 158.46 | 81.06 | 22.46 |
| AerialVLN-S-Val | FineCog-Nav | 1.97 | 1.50 | 1.85 | 11.47 | 130.32 | 75.28 | 34.52 |
Single-module ablations show that removing any module leads to performance drops, with the largest decline occurring when hierarchical memory is replaced by plain history. Joint ablations also degrade performance. The best results are achieved when all modules are enabled.
| Attn. | Imag. | Subgoal | Mem. | SR (%) | OSR (%) | NE (m) | nDTW (%) | S-SR (%) | S-OSR (%) | S-NE (m) |
|---|---|---|---|---|---|---|---|---|---|---|
| No | Yes | Yes | H | 3.00 | 7.00 | 104.38 | 19.55 | 19.92 | 26.46 | 66.21 |
| Yes | No | Yes | H | 3.67 | 5.00 | 101.27 | 19.67 | 20.48 | 24.21 | 64.85 |
| Yes | Yes | No | H | 2.00 | 4.33 | 102.32 | 19.13 | 19.42 | 24.28 | 65.54 |
| Yes | Yes | Yes | P | 0.67 | 2.67 | 97.76 | 19.69 | 19.42 | 23.50 | 62.90 |
| No | No | Yes | H | 3.67 | 8.67 | 106.59 | 18.14 | 19.35 | 27.30 | 70.16 |
| Yes | No | No | H | 4.00 | 8.67 | 98.75 | 19.78 | 16.68 | 26.46 | 65.36 |
| Yes | Yes | Yes | H | 6.00 | 9.00 | 91.43 | 22.48 | 22.03 | 27.23 | 59.02 |
Recall that AerialVLN-Fine provides sentence-level annotations for fine-grained evaluation. As the base LLM size increases, performance steadily improves. Small sentence-level differences can accumulate over long trajectories, leading to larger gaps in full-trajectory metrics.
| Base LLM | S-SR (%) | S-nDTW (%) | S-NE (m) |
|---|---|---|---|
| Gemini2.5-Flash-Lite | 16.40 | 26.33 | 79.00 |
| GPT-4o-mini | 19.56 | 28.58 | 65.96 |
| InternLM3-8B | 15.62 | 28.19 | 72.01 |
| ChatGLM-4-9B | 19.92 | 31.42 | 62.18 |
| InternLM2.5-20B | 19.00 | 34.11 | 67.67 |
| ChatGLM-4-32B | 15.95 | 23.20 | 62.67 |
| Qwen3-32B | 18.76 | 30.04 | 62.42 |
| Llama3.3-70B | 21.32 | 33.89 | 64.82 |
| Qwen2.5-72B | 22.03 | 35.37 | 59.02 |
Across all four tables, the results consistently support the same conclusion: a cognition-inspired, collaborative modular framework enables more reliable and interpretable zero-shot UAV navigation than both single-module prompting and existing multi-agent baselines.
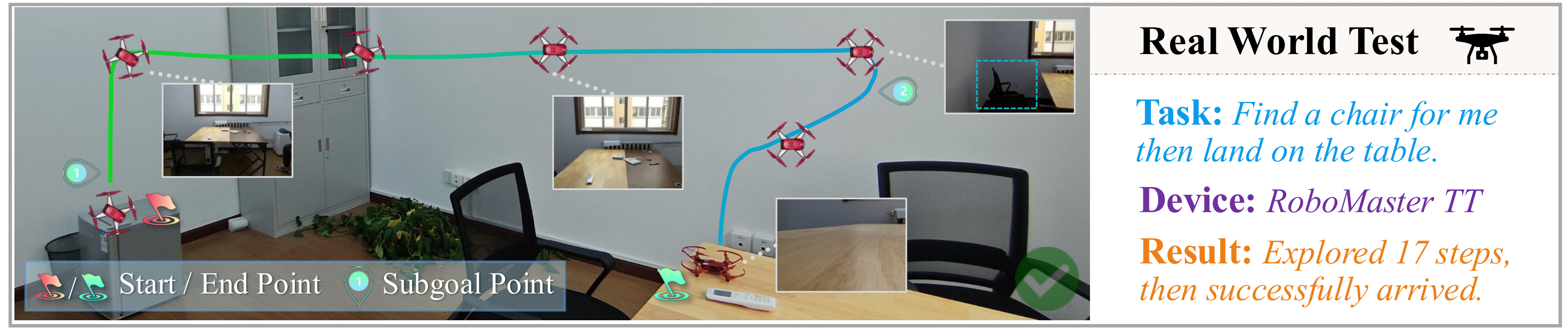
Real-World Deployment
To complement simulation results, we deploy FineCog-Nav on a RoboMaster TT UAV and conduct a preliminary real-world flight test. Given the instruction "Find a chair for me, then land on the table", the agent performs stepwise exploration, selects intermediate subgoals, and reaches the target after 17 steps.
Qualitative Analysis

Qualitative Navigation Trajectories
Representative trajectories show that the agent grounds language cues to visible landmarks and executes coherent subgoal transitions. Even in difficult cases, FineCog-Nav tends to keep instruction-consistent behavior rather than drifting early.
Human Study Results
Human study results further support the quantitative findings: participants generally prefer FineCog-Nav for instruction-following quality and perceived navigation intelligence.
AerialVLN-Fine Dataset
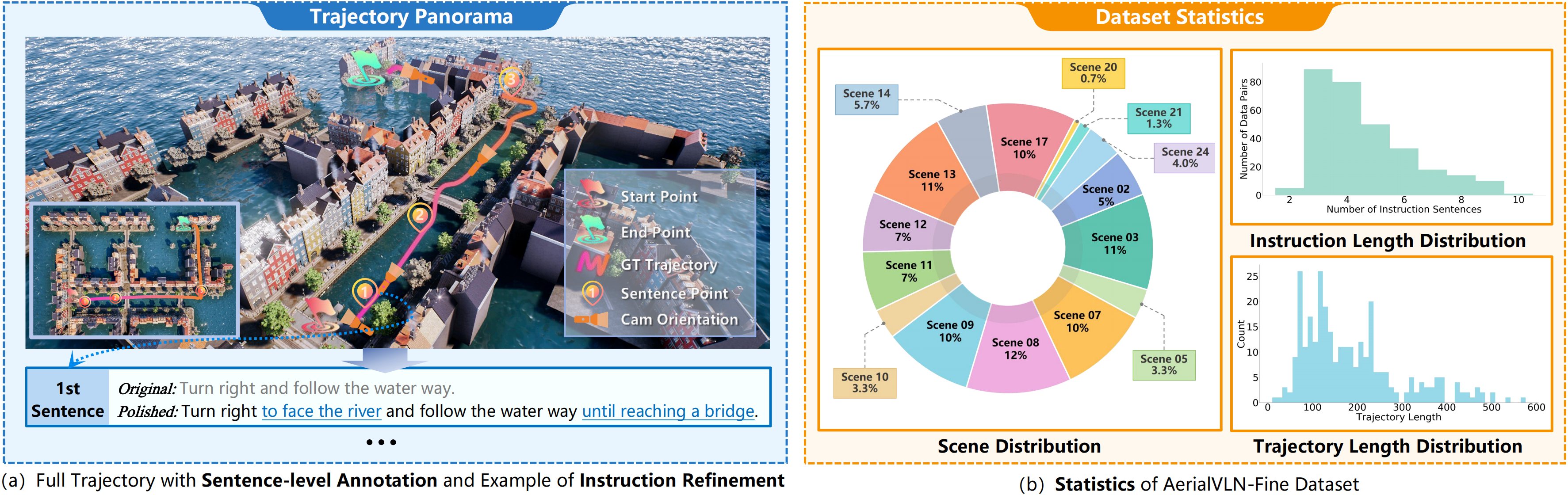
Overview of AerialVLN-Fine
AerialVLN-Fine is a curated benchmark built from AerialVLN for more reliable zero-shot UAV VLN evaluation. It provides sentence-level alignment between instruction segments and trajectory segments, and refines ambiguous expressions with explicit visual endpoints and landmark references.
The dataset is designed to support fine-grained capability diagnosis and sentence-level evaluation, while keeping annotation quality high through repeated manual verification.
Citation
@misc{shao2026finecognavintegratingfinegrainedcognitive,
title={FineCog-Nav: Integrating Fine-grained Cognitive Modules for Zero-shot Multimodal UAV Navigation},
author={Dian Shao and Zhengzheng Xu and Peiyang Wang and Like Liu and Yule Wang and Jieqi Shi and Jing Huo},
year={2026},
eprint={2604.16298},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.16298},
}Contact
For questions about this work, please contact:
shaodian@nwpu.edu.cn
|
isjieqi@nju.edu.cn